Hace tiempo que esta circulando la famosa teoría del internet muerto. Luego de un pequeño descuido en mi server me puse a meditar en que tal vez sea real.
Introducción
A saber cuando publicare esta entrada, pero a fecha del 18 de noviembre del 2025, estuve haciendo algo de limpieza en mi server. Como ya no iba a usar mas Apache2, decidí desinstalarlo. Aparte de un susto por haber usado apt purge apache2 de forma imprudente, tras salir un mensaje de que evitó borrar el directorio donde alojo mis webs, realmente no parecía haber ningún tipo de novedad. Pero se puso muy lento de repente. No tardé en darme cuenta de que pasaba algo y quise revisar. Lo primero que encontré, fue que los gráficos de mi VPS mostraban un consumo exageradisimo.
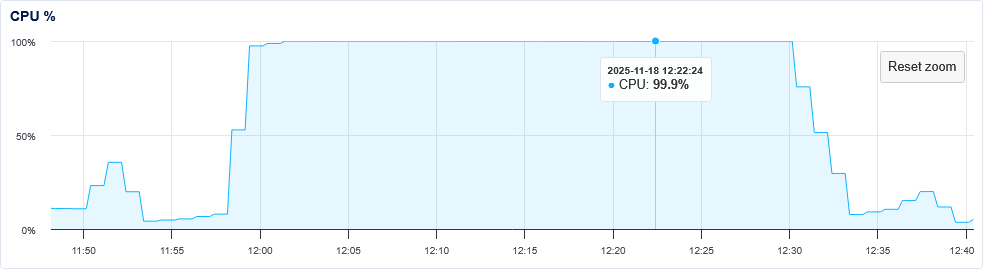
Rápidamente empece a revisar los logs. Era una cantidad asombrosa de llamadas desde un servidor chino al archivo xmlrpc.php que previamente habia deshabilitado por código y bloqueado por fail2ban. Si bien, al deshabilitarlo por código producía un error 405, produce un consumo excesivo de CPU por alguna razón que desconozco. Estoy actualmente en un proceso de limpieza del blog del cual luego hablaré, pero a pesar de eso, y mas los repetidos intentos de hacer no se que en ese archivo, empezaba a desbordarse los limitados recursos de mi procesador.
Tras lucharle un buen rato para entender lo que pasaba y resolverlo, encontré que el problema estaba en que al desinstalar Apache2, se borraron sus logs, pero fail2ban tenia reglas para apache, que comenzaron a fallar al no encontrar los logs que correspondían. Corregido eso, comenzó a aplicarse la regla que hice para que se bloqueen por iptables toda llamada a xmlrpc.php, porque al no usarlo, cualquiera que intente acceder a el seria sospechoso, asi que bastaba un solo intento para ser bloqueado por IP. Adjunto mi primitiva jaula llamada block_xmlrpc.conf en /etc/fail2ban/jail.d/
[block_xmlrpc] enabled = true filter = block_xmlrpc logpath = /var/log/nginx/*.access.log #port = http,https maxretry = 1 findtime = 3h bantime = 12h
y adjunto mi primitivo filtro block_xmlrpc.conf en /etc/fail2ban/filter.d/
[Definition] failregex = ^<HOST>.*"(GET|POST) .*(\.env|xmlrpc\.php|\.git)
En realidad una tarea muy facil de resolver, pero que me deja reflexionando sobre algo
La teoría del internet muerto
Esta teoría ha estado ganando popularidad y siento que … tal vez no esta demasiado equivocada.
La teoría de Internet muerta (también conocida como Internet muerta o la teoría de la conspiración de Internet muerta) es una teoría de conspiración que afirma que desde alrededor de 2016 Internet ha consistido principalmente en la actividad de bots y ha generado automáticamente contenido manipulado por la curación algorítmica, como parte de un esfuerzo coordinado e intencional para controlar la población y minimizar la actividad humana orgánica. Los defensores de la teoría creen que estos bots sociales fueron creados intencionalmente para ayudar a controlar los algoritmos y aumentar los resultados de búsqueda con el fin de influir en los consumidores. Algunos defensores de la teoría acusan a las agencias gubernamentales de usar bots para manipular la percepción pública. La teoría de Internet muerta ha ganado tracción porque muchos de los fenómenos observados son cuantificables, como el aumento del tráfico de bots, pero la literatura sobre el tema no apoya la teoría completa
Tal vez la parte conspiranoica no sea real. La verdad, me da bastante igual si lo es, pero es increíble la cantidad de trafico no orgánico que hay en internet.
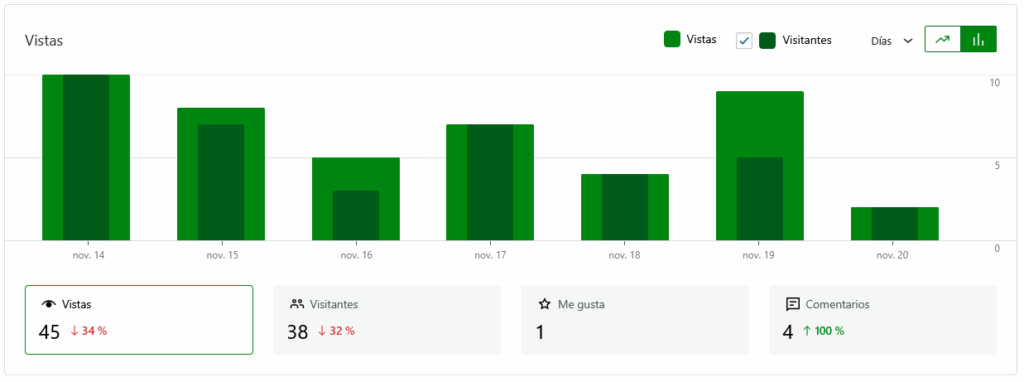
Actualmente tengo un promedio de visitantes de 35 personas por semana. No tengo la certeza de que haya 35 personas humanas leyendo mis contenidos, porque no comentan. Lo que muestra como comentarios solo son los pingback que los tengo activados y el me gusta que aparece, es el que me dio un usuario del fediverso @pragmaticdx, posiblemente, el único lector humano que puedo confirmar desde mi web.
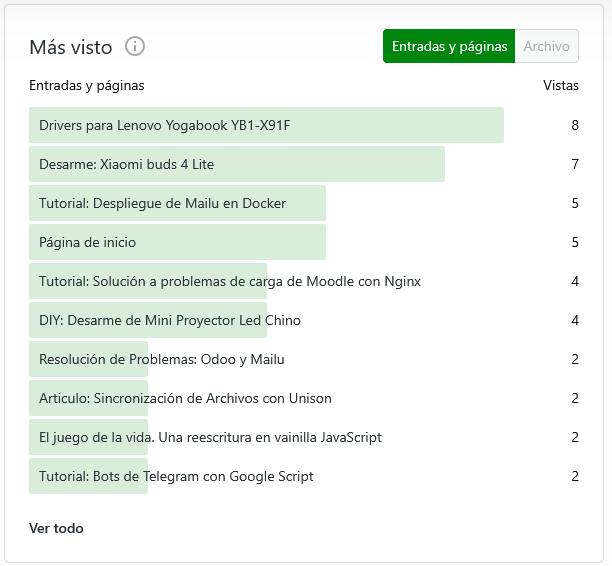
¿Por que dudo tanto de mis lectores? ¿Por la tendencia de estos artículos? No realmente. Esto es una curiosidad, tal vez consecuencia del SEO. Encuentro raro que haya 7 personas leyendo un articulo tan viejo, pero encuentro sumamente raro que esta tendencia se haya mantenido en las estadísticas de los últimos 12 meses.
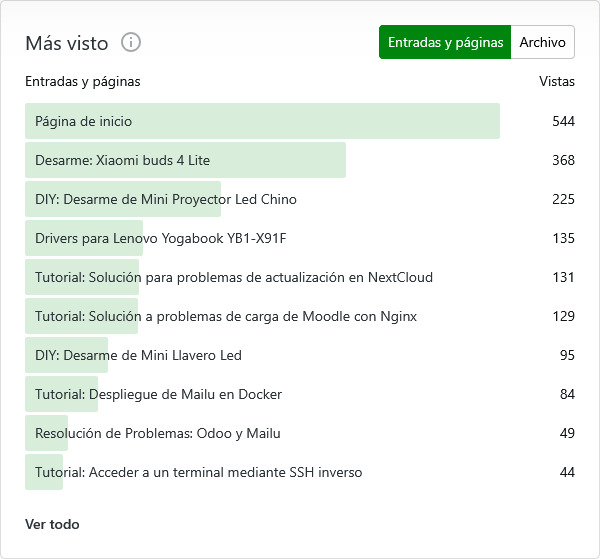
¿Por que habrían 368 personas buscando y leyendo sobre el desarme de unos xiaomi buds 4 lite, o buscando drivers para lenovo yogabook, o el desarme de un proyector chino? No tengo idea. Le sospecho menos a los de resolución de problemas como los de nextcloud o mailu. Pero el punto es el siguiente.
35 usuarios a la semana no producen tanto trafico
Jetpack filtra las estadísticas de tal manera que solo, en teoría, se muestre el trafico orgánico. Es decir, ignora todo el trafico aparte del que considera humano. Así que utilizando GoAccess filtré el trafico registrado en los logs a un periodo 24 de octubre al 20 de noviembre de 2025, para ver el total de trafico que llegaba unicamente a ese sitio web.
| Total Requests | 195.987 |
| Valid Requests | 195.987 |
| Failed Requests | 0 |
| Unique Visitors | 20.732 |
| Requested Files | 20.509 |
| Referrers | 0 |
| Not Found | 3041 |
| Static Files | 107 |
| Tx. Amount | 1.29 GiB |
Un monstruoso trafico de 1.29GiB
Estuve revisando los logs y si bien una parte importante del trafico es generada por el plugin de activityPub. otra parte importante esta generada por actores desconocidos.
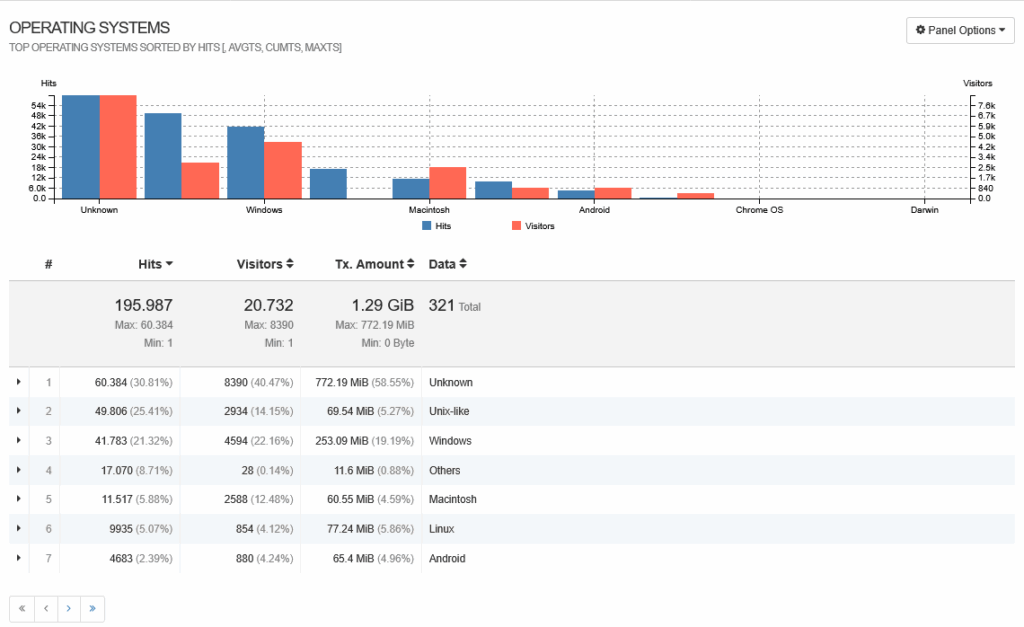
Hay un 20.47% de trafico (60.384 peticiones en el intervalo de tiempo dado) generado por sistemas operativos desconocidos. Esto es, probablemente crawlers maliciosos que escanean la red en busca de vulnerabilidades. Por supuesto que no les interesa identificarse.
Y claro, tenemos a los que se identifican como «otros» que incluyen hasta teléfonos que ni navegadores tenían
| 17.053 (8.70%) | 15 (0.07%) | 11.52 MiB (0.87%) | Apache-HttpClient/4.5.2 |
| 3 (0.00%) | 1 (0.00%) | 32.4 KiB (0.00%) | Apache-HttpClient |
| 2 (0.00%) | 2 (0.01%) | 384 B (0.00%) | Apache-HttpClient/4.5.13 |
| 2 (0.00%) | 1 (0.00%) | 24.7 KiB (0.00%) | SonyEricssonW850i/R1ED |
| 2 (0.00%) | 1 (0.00%) | 24.7 KiB (0.00%) | BlackBerry9530/4.7.0.167 |
| 2 (0.00%) | 2 (0.01%) | 10 B (0.00%) | SymbianOS/9.2 |
| 1 (0.00%) | 1 (0.00%) | 5 B (0.00%) | SonyEricssonK800i/R1CB |
| 1 (0.00%) | 1 (0.00%) | 5 B (0.00%) | SymbianOS/8.0 |
| 1 (0.00%) | 1 (0.00%) | 5 B (0.00%) | BlackBerry9700/5.0.0.351 |
| 1 (0.00%) | 1 (0.00%) | 5 B (0.00%) | BlackBerry9000/4.6.0.167 |
| 1 (0.00%) | 1 (0.00%) | 5 B (0.00%) | BlackBerry8300/4.2.2 |
| 1 (0.00%) | 1 (0.00%) | 5 B (0.00%) | SonyEricssonK610i/R1CB |
Estas peticiones raras, también pueden ser actores maliciosos automatizados que están dando vueltas por internet
Ahora bien, también hay agentes de usuarios extraños.
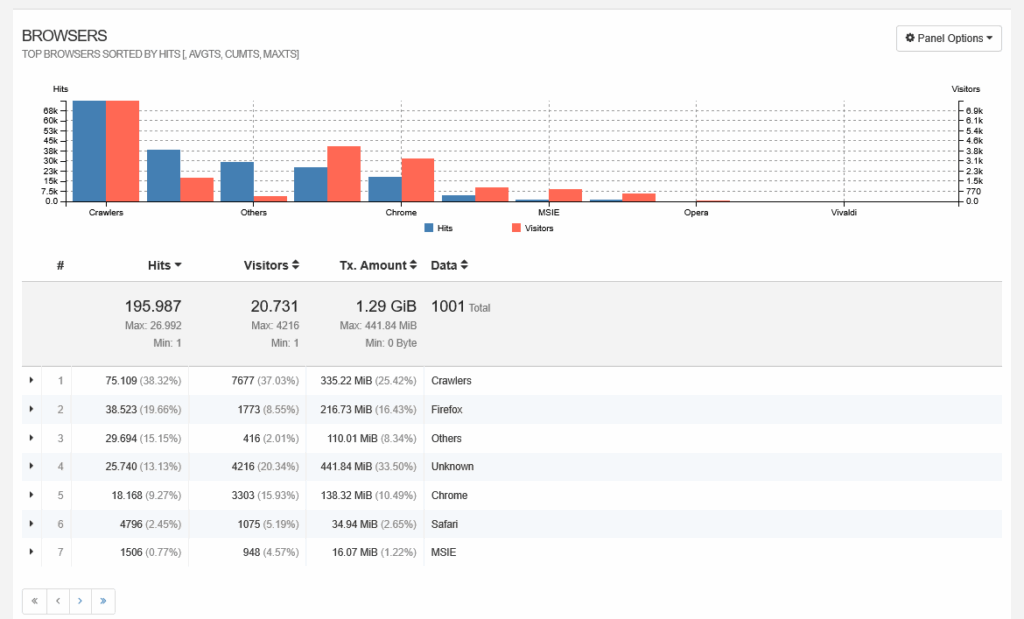
Cerca del 37% de mi trafico es claramente Crawlers.
| 75.109 (38.32%) | 7677 (37.03%) | 335.22 MiB (25.42%) | Crawlers |
| 26.992 (13.77%) | 2235 (10.78%) | 39.44 MiB (2.99%) | (http.rb/5.3.1 |
| 18.457 (9.42%) | 95 (0.46%) | 3.84 MiB (0.29%) | (Mastodon/4.1.25 |
| 6817 (3.48%) | 26 (0.13%) | 2.07 MiB (0.16%) | robot |
| 3087 (1.58%) | 294 (1.42%) | 4.63 MiB (0.35%) | (http.rb/5.2.0 |
| 2377 (1.21%) | 56 (0.27%) | 24.61 MiB (1.87%) | Barkrowler/0.9 |
| 1643 (0.84%) | 19 (0.09%) | 15.28 MiB (1.16%) | GPTBot/1.2 |
| 1433 (0.73%) | 1379 (6.65%) | 21.26 MiB (1.61%) | AhrefsBot/7.0 |
| 1376 (0.70%) | 191 (0.92%) | 28.19 MiB (2.14%) | Googlebot/2.1 |
| 1286 (0.66%) | 13 (0.06%) | 25.47 MiB (1.93%) | BLEXBot/1.0 |
| 1083 (0.55%) | 537 (2.59%) | 20.84 MiB (1.58%) | SemrushBot/7~bl |
| 762 (0.39%) | 26 (0.13%) | 6.5 MiB (0.49%) | DataForSeoBot/1.0 |
| 759 (0.39%) | 600 (2.89%) | 13.55 MiB (1.03%) | bingbot/2.0 |
| 737 (0.38%) | 48 (0.23%) | 10.36 MiB (0.79%) | Parser |
| 644 (0.33%) | 26 (0.13%) | 4.45 MiB (0.34%) | DotBot/1.2 |
| 611 (0.31%) | 1 (0.00%) | 9.9 MiB (0.75%) | bot |
| 603 (0.31%) | 26 (0.13%) | 2.64 MiB (0.20%) | (Takahe/0.10.0-dev |
| 586 (0.30%) | 543 (2.62%) | 10.31 MiB (0.78%) | Amazonbot/0.1 |
| 568 (0.29%) | 7 (0.03%) | 6.29 MiB (0.48%) | GPTBot/1.3 |
Solo puse esta vez unos cuantos de la enorme lista que sale en la vista de crawlers. Teóricamente no son maliciosos, pero es una cantidad importante de trafico en mi sitio web. Aun así es posible de ver muchos crawlers de GPT en diferentes versiones.
Conclusiones
Me sigo esforzando para que mi sitio sea mas ligero. Mi objetivo actual es que sea perfectamente navegable mediante el navegador elinks pero que también sea mas ligero para dar una respuesta mas rápida. Pero realmente no se si humanos visiten mi blog. La abrumadora cantidad de bots y crawlers que llegan solo a robarse mi contenido o directamente intentar causarme algún mal me hace pensar que tal vez y si, el internet esta muerto. Pero tampoco hago mucho por alcanzar cierta difusión. Por el momento solo les dejo un video de Caleon que habla del tema, porque o no hay conclusión o la conclusión es que no hay nadie en internet.
Actualización
No tengo idea de por que se han vuelto tan insistentes en atacar el archivo xmlrpc.php. Fail2ban hace un buen trabajo bloqueando a los intensos, pero hay tantos desde tantas direcciones IP distintas y con tan poca diferencia de tiempo entre si, que pienso que es un mismo autor pero diferentes IP
Una respuesta a “Analisis de Logs: El internet muerto parece real”
[…] El 2025 estuvo dominado por el tema BlockMag, con el cual parece que estaré parte del 2026 pues le tengo dudas y quiero simplificar la administración del sitio. La idea de los bloques de WordPress me gusta, pero a la larga es súper pesado y tedioso. Dado que soy desarrollador web, puedo intentar lucirme con trabajos algo mas manuales y no depender tanto de plugins. En cuanto a trafico, no hubo cambio. La pagina de inicio recibió 522 vistas en el 2024 y en 2025 561. en ese sentido, la incursión de la inteligencia artificial solo agregó un origen nuevo al trafico, pero no lo incrementó. Así que escribir mas no atrae mas gente. Pero por supuesto que atrae crawlers. […]